本文共 3114 字,大约阅读时间需要 10 分钟。
Battle City
| Time Limit: 1000MS | | Memory Limit: 65536K |
| Total Submissions: 9885 | | Accepted: 3285 |
Description
Many of us had played the game "Battle city" in our childhood, and some people (like me) even often play it on computer now.

What we are discussing is a simple edition of this game. Given a map that consists of empty spaces, rivers, steel walls and brick walls only. Your task is to get a bonus as soon as possible suppose that no enemies will disturb you (See the following picture).
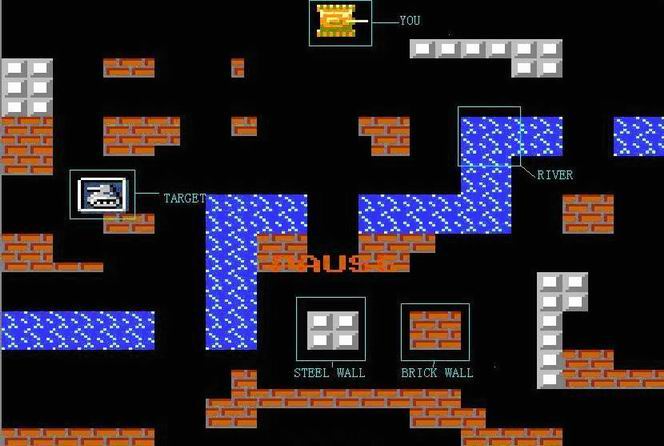
Your tank can't move through rivers or walls, but it can destroy brick walls by shooting. A brick wall will be turned into empty spaces when you hit it, however, if your shot hit a steel wall, there will be no damage to the wall. In each of your turns, you can choose to move to a neighboring (4 directions, not 8) empty space, or shoot in one of the four directions without a move. The shot will go ahead in that direction, until it go out of the map or hit a wall. If the shot hits a brick wall, the wall will disappear (i.e., in this turn). Well, given the description of a map, the positions of your tank and the target, how many turns will you take at least to arrive there?
Input
The input consists of several test cases. The first line of each test case contains two integers M and N (2 <= M, N <= 300). Each of the following M lines contains N uppercase letters, each of which is one of 'Y' (you), 'T' (target), 'S' (steel wall), 'B' (brick wall), 'R' (river) and 'E' (empty space). Both 'Y' and 'T' appear only once. A test case of M = N = 0 indicates the end of input, and should not be processed.
Output
For each test case, please output the turns you take at least in a separate line. If you can't arrive at the target, output "-1" instead.
Sample Input
3 4YBEBEERESSTE0 0
Sample Output
8
题意
n*m的矩阵,Y代表起点,T代表终点,R不能通过,走E需要一步,B需要两步。求从起点到终点的最短距离。如果不能到达,输出-1
AC代码
#include #include #include #include #include #include #include
转载地址:http://dcbp.baihongyu.com/